哈 尔 滨 理 工 大 学
毕业设计开题报告
题 目: 基于Spark的股票大数据分析及可视化系统
院 系: 计算机科学与技术学院
数据科学与大数据技术系
2023年10月
一、选题的依据、意义,理论或实际方面的价值
1.选题的依据和意义
近年来,因全球经济不确定性、地缘政治紧张局势以及供应链问题等多个因素共同作用,导致投资者持保守态度,观望情绪浓厚,市场表现相对疲软。股票价格普遍下跌。这导致了许多行业遭受了巨大挑战。因此,在股票市场日益疲软的情况下,研究和分析股票指标动向极其重要。实时股票大数据分析和可视化是也是金融学,量化金融等相关领域的重要组成部分,如果无法解决这个问题将直接影响到金融和量化金融的发展。实时股票大数据分析和可视化也可以为股票行业提供更多的商业价值。例如,股票市场研究机构可以通过数据分析和可视化技术来发现市场的机会和趋势,为投资者提供更有价值的信息和建议。
因此,本文将从实际出发,在分析股票动向的基础上,从A股数据方面研究出股票整体趋势以及近期未来走向,进而对相应行业与投资者提出投资方案和建议对策,促进股票行业以及金融投资发展。
2.理论或实际应用方面的价值
(1)理论价值:
本毕业设计课题的研究,有助于加强对股票市场的动态特征以及如何将股票市场动态特征量化分析的理解:通过对股票市场的大规模数据进行分析,可以深入理解股票市场的动态变化、价格波动、交易量等方面的特征的量化方法与细节。便于积累经验用于以后更加新颖和复杂的数据分析过程中的理论价值。
其次,本毕业设计能够深化对Spark大数据处理框架的业务逻辑对实际数据分析以及投资组合优化的认识。可以充分地认识到如何利用Spark大数据框架提供的基础计算服务以及算法的搭配只用来实现对股票数据的充分挖掘以及投资组合的优化和构建。
基于Spark的股票大数据分析系统可以通过数据可视化工具将数据转化为直观的图表和图形,帮助用户更好地理解数据和发现潜在的模式。这有助于提高研究人员和投资者对股票市场的洞察力,促进更深入的认识和决策。
(2)实际价值:
实时数据处理和决策支持:Spark的分布式计算能力使得系统能够处理大规模的实时股票数据,包括股票价格、交易量、市场指标等。这有助于实时监测市场动态并及时做出决策,例如快速识别市场趋势、捕捉投资机会或进行高频交易。
投资组合优化和风险管理:通过Spark进行股票大数据分析,系统可以识别和分析大量股票的历史数据和基本面信息,帮助投资者优化投资组合并管理风险。系统可以基于历史数据和模型进行预测和模拟,提供投资组合配置方案和风险评估,从而帮助投资者做出更明智的投资决策。
科学研究和市场预测:基于Spark的股票大数据分析系统为学术研究人员提供了强大的工具和平台,用于深入研究股票市场的规律和行为。此外,系统还可以支持市场预测模型的开发和评估,为投资者和机构提供更准确的市场预测和建议。
二、国内外研究现状
1.国内现状:
(1)学术研究:在国内的高校和研究机构中,已经有一些学者和研究人员致力于基于Spark的股票大数据分析及可视化系统的研究。他们通过实际股票数据的分析和处理,探索了不同的数据挖掘和机器学习算法,以及可视化技术在股票市场的应用。
(2)金融行业:国内的金融机构和投资公司也开始关注和应用基于Spark的股票大数据分析及可视化系统。他们借助Spark的分布式计算能力,处理和分析海量的股票数据,以支持投资决策、风险控制和交易策略的制定。
(3)商业应用:一些国内的科技公司和数据服务提供商也开始提供基于Spark的股票大数据分析及可视化系统的商业解决方案。他们开发了具有实时数据处理和交互式可视化功能的系统,为投资者和分析师提供个性化的数据分析和决策支持服务。
2.国外现状
(1)学术研究:国外的学术界对基于Spark的股票大数据分析及可视化系统的研究也非常活跃。一些研究机构和大学开展了相关的研究项目,探索了不同的数据分析算法、机器学习模型和可视化技术在股票市场的应用。
(2)金融行业:国际上的金融机构和投资公司也在积极应用基于Spark的股票大数据分析及可视化系统。他们利用Spark的高性能和可扩展性,处理和分析海量的股票数据,以提供更准确和实时的投资决策支持。
(3)创业公司:一些国外的创业公司专注于开发和提供基于Spark的股票大数据分析及可视化系统。它们通过创新的技术和用户友好的界面,为投资者和分析师提供强大的数据分析和可视化功能,帮助他们更好地理解和利用股票市场数据。
综上所述,基于Spark的股票大数据分析及可视化系统在国内外都已经引起了广泛的关注和研究。学术界、金融行业和商业领域都在积极探索和应用相关技术和系统,以提高股票市场分析和决策的效率和准确性。
三、课题研究的内容及拟采取的方法
1.课题研究的内容
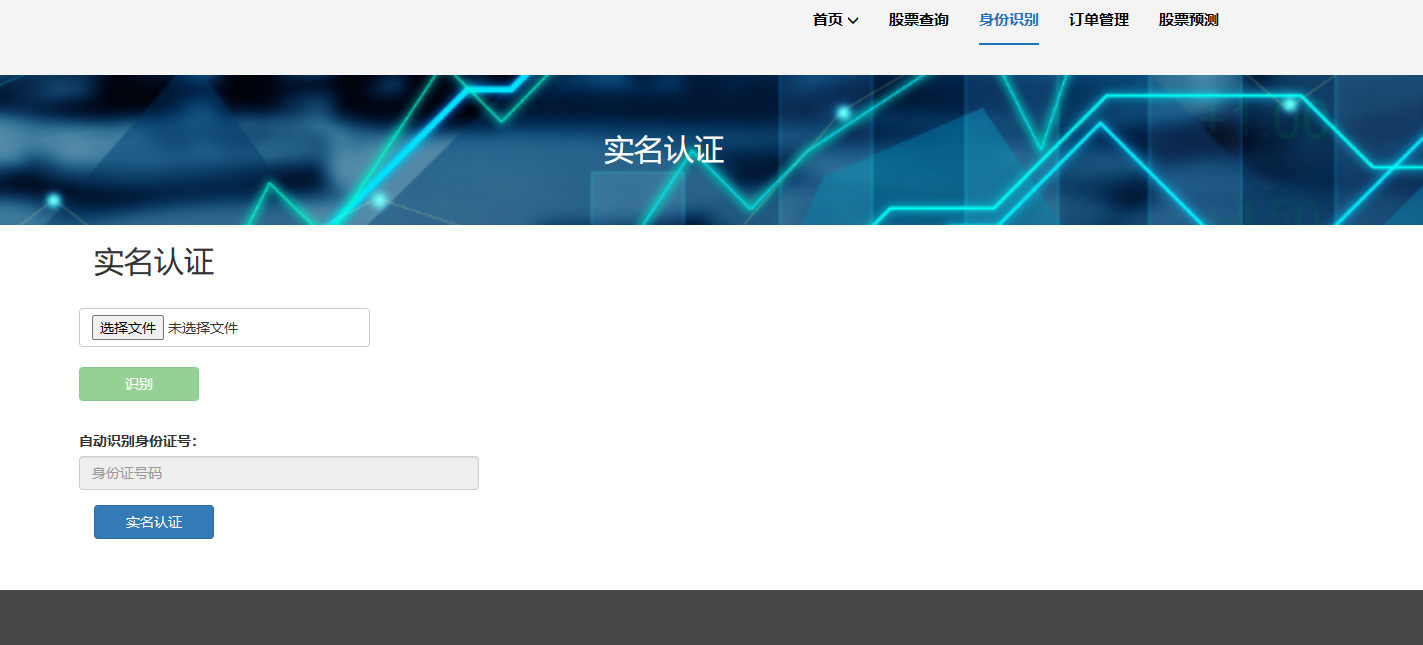
(1)数据采集与清洗:设计和实现数据采集模块,从不同的数据源(如股票交易所、财经网站等)获取股票市场的相关数据,包括股票价格、交易量、财务数据等。并且进行数据清洗和预处理,处理缺失值、异常值和噪声,确保数据的质量和准确性。
(2)数据存储与管理:选择合适的分布式存储系统,如HDFS用于存储股票市场的大规模数据。并设计和实现数据管理模块,包括数据的存储、读取和查询等操作,以支持后续的数据分析和可视化需求。
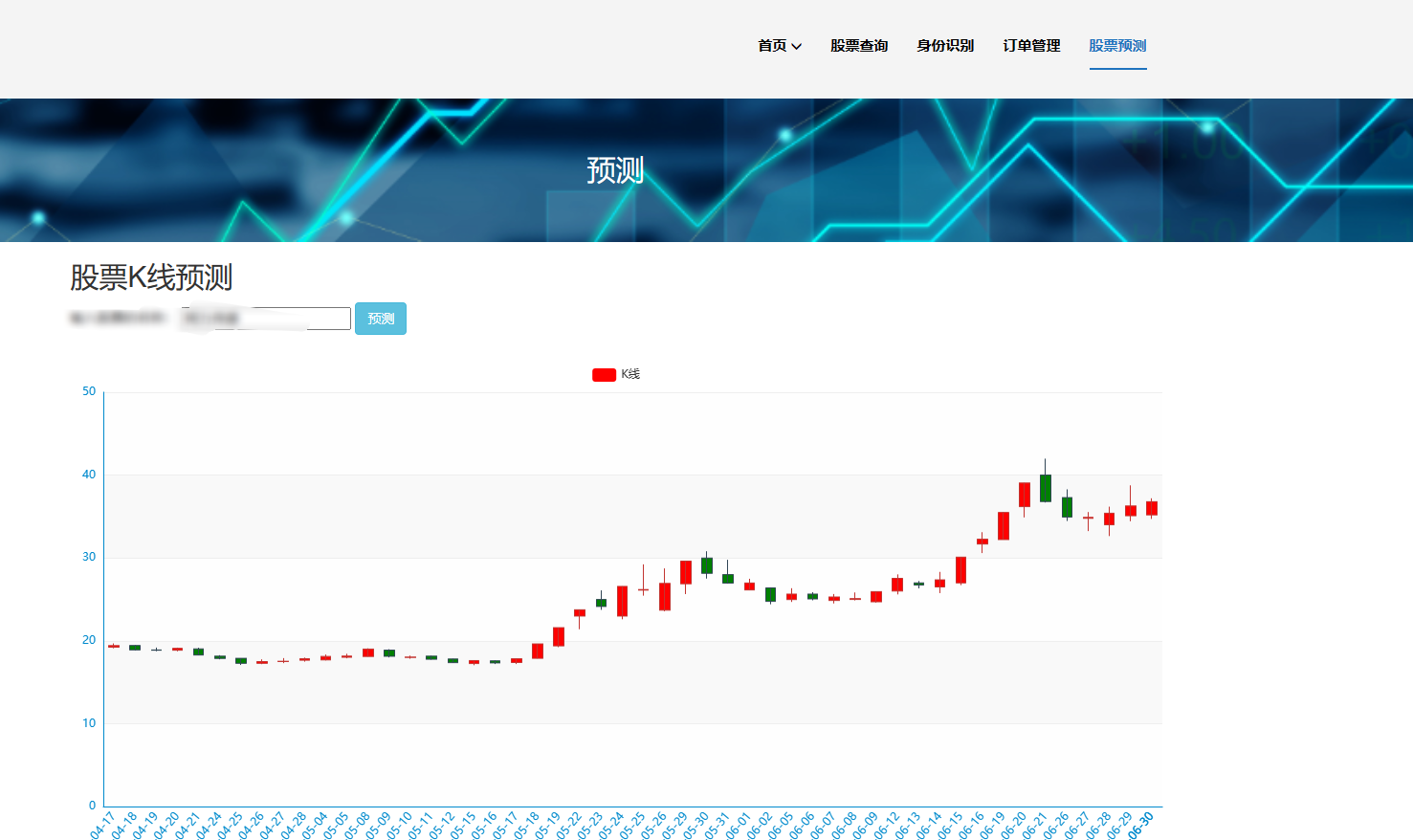
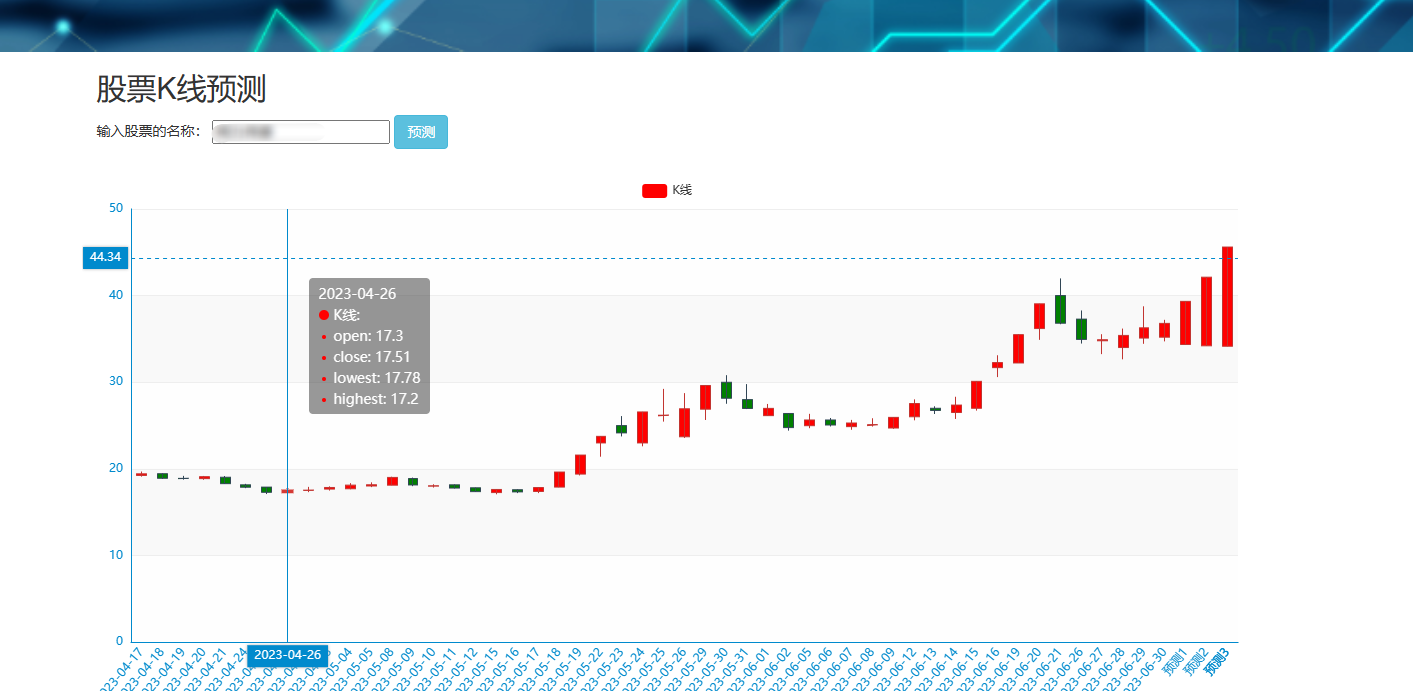
(3)数据分析与建模:利用Spark的分布式计算能力,设计和实现数据分析模块,应用机器学习算法、统计分析方法等,对股票市场数据进行分析和建模。并且实现股票价格预测、市场趋势分析、相关性分析等功能,为投资决策和风险控制提供支持。
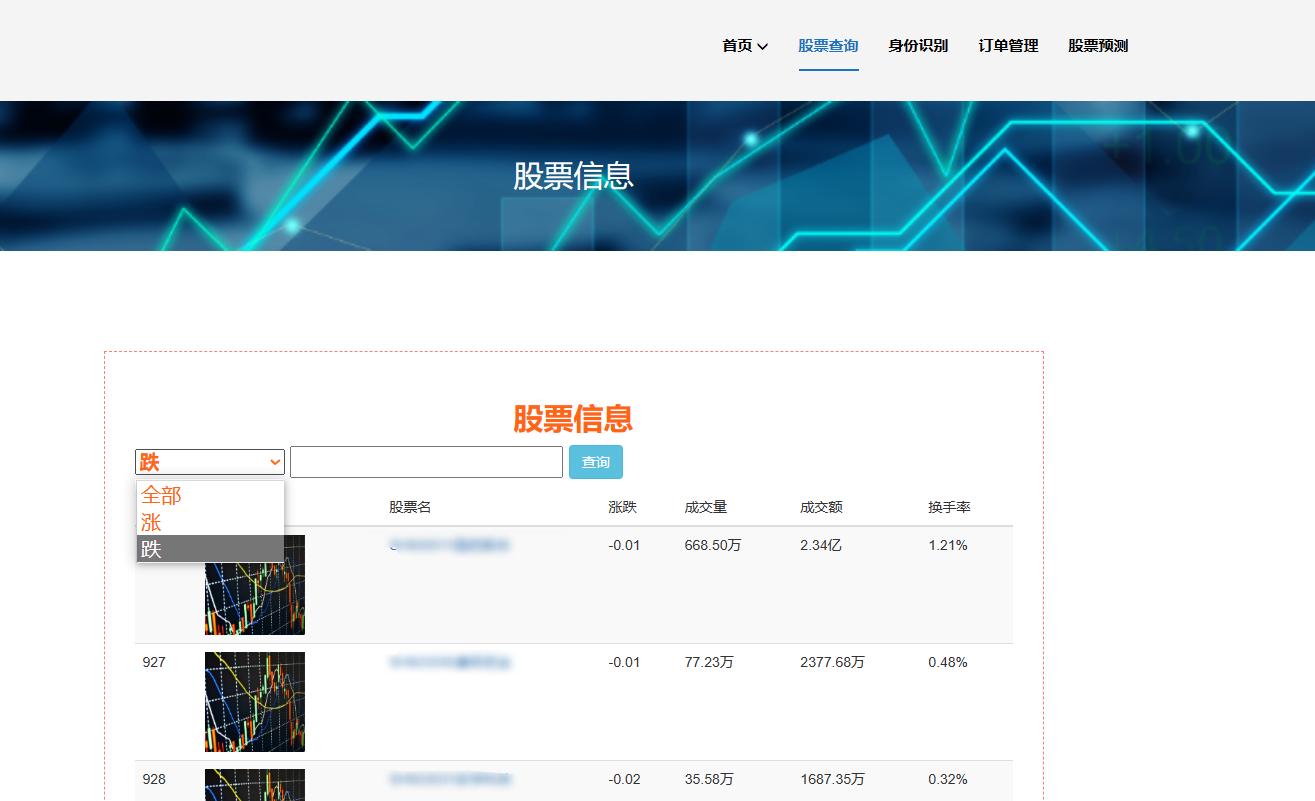
(4)可视化与交互:设计和实现可视化模块,通过图表、图形等方式将股票市场数据以可视化形式展示。其次提供交互式界面,允许用户自定义数据展示、进行数据筛选和排序,以及与可视化结果进行交互操作。
(5)性能优化扩展以及评估:对系统进行性能优化以及扩展性,通过合理的数据分区、并行计算和缓存机制的调配,提高数据处理和分析的效率,以及考虑系统的扩展性,支持处理更大规模的股票市场数据和更复杂的分析任务,并分析和总结实验结果,评估系统的准确性、效率和用户体验
基于以上分析,本设计系统的大致结构如下图1所示:
图1 功能结构图
2.课题研究拟采取的方法
本课题将采用的技术方法包括:面向对象方法论、软件系统分析与设计、可视化建模、程序设计、数据库技术、计算机网络技术以及中英文写作能力,并借鉴了目前已有的一些高校与社区的系统进行设计。
(1)文献法研究法:通过调查与网页设计制作相关的文献,对其进行一个综合性的了解,同时吸收文献中对网页设计制作的独特见解,加入自身的理解,从而达到更高的程度。
(2)描述性研究法:将网上已有的网页制作的经验、理论以及规律甚至是小技巧等等通过自己的理解,并给予实施验证。
(3)实验研究法:对网站的各个功能模块进行软件测试。
本系统的设计将会采用查阅书籍、浏览网站资料、前往企业现场等方式来对系统的实现进行研究和梳理,通过对实际企业员工进行用户交流、考察提高用户体验以及系统功能的设计和改进。
论文撰写方面将会通过调查法、观察法、经验总结法等,对收集到的信息和资料进行梳理,结合实际的系统设计、实现和测试维护进行论证,最终在导师的指导下完成论文的撰写。
四、课题研究中的主要难点及解决办法
1. 数据处理和存储
股票市场的数据量庞大且变化频繁,对数据的处理和存储提出了挑战。解决办法可以包括:
(1)数据分区和分片:使用Spark的分布式计算能力,将大规模数据划分为多个分区,实现并行处理和计算。
(2)高效存储:选择适合大数据处理的分布式存储系统,例如Hadoop Distributed File System(HDFS)或Apache Parquet,以实现高性能的数据读写和查询。
2. 数据清洗和转换
原始股票数据可能存在缺失值、异常值和噪声等问题,需要进行数据清洗和转换。解决办法可以包括:
(1)缺失值处理:通过插值、删除或填充缺失值的方法来处理缺失数据。
(2)异常值检测和处理:使用统计方法或机器学习算法来检测和处理异常值。
(3)特征工程:对原始数据进行特征提取、转换和降维,以便更好地适应数据分析和可视化需求。
3. 大数据分析算法
股票市场的数据具有复杂性和高维性,选择合适的大数据分析算法是一个挑战。解决办法可以包括:
(1)机器学习算法:使用机器学习算法,如回归、分类、聚类和时间序列分析等,来预测股票价格、研究市场趋势和发现相关性。
(2)图计算算法:利用图计算算法,如PageRank算法和社区发现算法,分析股票市场的网络结构和关联关系。
(3)高性能计算:通过合理的算法设计和并行计算技术,充分利用Spark的计算能力,提高大数据分析的效率和准确性。
基于以上分析,本设计中使用了k均值算法,如图2。
图2 k均值算法流程图
4. 可视化设计和交互性
将股票大数据以可视化形式呈现给用户,需要考虑设计合理的可视化方法和提供良好的交互性。解决办法可以包括:
(1)可视化技术选择:选择合适的可视化图表、图形和布局,以准确传达数据的含义和趋势。
(2)用户交互设计:设计交互式界面,提供用户友好的操作方式,例如缩放、过滤、排序和联动等功能,以便用户深入探索和分析数据。
(3)可视化性能优化:对大规模数据的可视化进行性能优化,避免过多的计算和绘制,以提高系统的响应速度和用户体验。
以上是在研究基于Spark的股票大数据分析及可视化系统时可能遇到的主要难点及相应的解决办法。通过深入研究和充分利用Spark的分布式计算能力,结合合适的数据处理、分析算法和可视化技术,可以克服这些难点,实现一个高效、准确和用户友好的股票大数据分析及可视化系统。
五、进度安排
1、选题与需求分析阶段(2023.09.11-2023.10.22)
2023.09.11-2023.09.24:完成技术调查与选题。
2023.09.25-2023.10.22:完成《开题报告》、《项目需求说明书》。
2、系统设计阶段(2023.10.23-2023.12.17)
2023.10.23-2023.11.19:进行概要设计并撰写《概要设计说明书》。
2023.11.20-2023.12.17:进行详细设计并撰写《详细设计说明书》、《中期检查报告》。
3、系统实现阶段(2023.12.18-2024.03.31)
2023.12.18-2024.03.17:完成系统编码和单元测试。
2024.03.18-2024.03.31:完成系统的集成测试并修改bug。
- 毕业设计答辩阶段(2024.04.01-2024.06.20)
2024.04.01-2024.05.31:撰写毕业设计论文。
2024.06.01-2024.06.14:修改毕业论文,制作答辩PPT。
2024.06.15-2024.06.20:毕业答辩。
哈 尔 滨 理 工 大 学
毕业设计开题报告
题 目: 基于Spark的股票大数据分析及可视化系统
院 系: 计算机科学与技术学院
数据科学与大数据技术系
2023年10月
一、选题的依据、意义,理论或实际方面的价值
1.选题的依据和意义
近年来,因全球经济不确定性、地缘政治紧张局势以及供应链问题等多个因素共同作用,导致投资者持保守态度,观望情绪浓厚,市场表现相对疲软。股票价格普遍下跌。这导致了许多行业遭受了巨大挑战。因此,在股票市场日益疲软的情况下,研究和分析股票指标动向极其重要。实时股票大数据分析和可视化是也是金融学,量化金融等相关领域的重要组成部分,如果无法解决这个问题将直接影响到金融和量化金融的发展。实时股票大数据分析和可视化也可以为股票行业提供更多的商业价值。例如,股票市场研究机构可以通过数据分析和可视化技术来发现市场的机会和趋势,为投资者提供更有价值的信息和建议。
因此,本文将从实际出发,在分析股票动向的基础上,从A股数据方面研究出股票整体趋势以及近期未来走向,进而对相应行业与投资者提出投资方案和建议对策,促进股票行业以及金融投资发展。
2.理论或实际应用方面的价值
(1)理论价值:
本毕业设计课题的研究,有助于加强对股票市场的动态特征以及如何将股票市场动态特征量化分析的理解:通过对股票市场的大规模数据进行分析,可以深入理解股票市场的动态变化、价格波动、交易量等方面的特征的量化方法与细节。便于积累经验用于以后更加新颖和复杂的数据分析过程中的理论价值。
其次,本毕业设计能够深化对Spark大数据处理框架的业务逻辑对实际数据分析以及投资组合优化的认识。可以充分地认识到如何利用Spark大数据框架提供的基础计算服务以及算法的搭配只用来实现对股票数据的充分挖掘以及投资组合的优化和构建。
基于Spark的股票大数据分析系统可以通过数据可视化工具将数据转化为直观的图表和图形,帮助用户更好地理解数据和发现潜在的模式。这有助于提高研究人员和投资者对股票市场的洞察力,促进更深入的认识和决策。
(2)实际价值:
实时数据处理和决策支持:Spark的分布式计算能力使得系统能够处理大规模的实时股票数据,包括股票价格、交易量、市场指标等。这有助于实时监测市场动态并及时做出决策,例如快速识别市场趋势、捕捉投资机会或进行高频交易。
投资组合优化和风险管理:通过Spark进行股票大数据分析,系统可以识别和分析大量股票的历史数据和基本面信息,帮助投资者优化投资组合并管理风险。系统可以基于历史数据和模型进行预测和模拟,提供投资组合配置方案和风险评估,从而帮助投资者做出更明智的投资决策。
科学研究和市场预测:基于Spark的股票大数据分析系统为学术研究人员提供了强大的工具和平台,用于深入研究股票市场的规律和行为。此外,系统还可以支持市场预测模型的开发和评估,为投资者和机构提供更准确的市场预测和建议。
二、国内外研究现状
1.国内现状:
(1)学术研究:在国内的高校和研究机构中,已经有一些学者和研究人员致力于基于Spark的股票大数据分析及可视化系统的研究。他们通过实际股票数据的分析和处理,探索了不同的数据挖掘和机器学习算法,以及可视化技术在股票市场的应用。
(2)金融行业:国内的金融机构和投资公司也开始关注和应用基于Spark的股票大数据分析及可视化系统。他们借助Spark的分布式计算能力,处理和分析海量的股票数据,以支持投资决策、风险控制和交易策略的制定。
(3)商业应用:一些国内的科技公司和数据服务提供商也开始提供基于Spark的股票大数据分析及可视化系统的商业解决方案。他们开发了具有实时数据处理和交互式可视化功能的系统,为投资者和分析师提供个性化的数据分析和决策支持服务。
2.国外现状
(1)学术研究:国外的学术界对基于Spark的股票大数据分析及可视化系统的研究也非常活跃。一些研究机构和大学开展了相关的研究项目,探索了不同的数据分析算法、机器学习模型和可视化技术在股票市场的应用。
(2)金融行业:国际上的金融机构和投资公司也在积极应用基于Spark的股票大数据分析及可视化系统。他们利用Spark的高性能和可扩展性,处理和分析海量的股票数据,以提供更准确和实时的投资决策支持。
(3)创业公司:一些国外的创业公司专注于开发和提供基于Spark的股票大数据分析及可视化系统。它们通过创新的技术和用户友好的界面,为投资者和分析师提供强大的数据分析和可视化功能,帮助他们更好地理解和利用股票市场数据。
综上所述,基于Spark的股票大数据分析及可视化系统在国内外都已经引起了广泛的关注和研究。学术界、金融行业和商业领域都在积极探索和应用相关技术和系统,以提高股票市场分析和决策的效率和准确性。
三、课题研究的内容及拟采取的方法
1.课题研究的内容
(1)数据采集与清洗:设计和实现数据采集模块,从不同的数据源(如股票交易所、财经网站等)获取股票市场的相关数据,包括股票价格、交易量、财务数据等。并且进行数据清洗和预处理,处理缺失值、异常值和噪声,确保数据的质量和准确性。
(2)数据存储与管理:选择合适的分布式存储系统,如HDFS用于存储股票市场的大规模数据。并设计和实现数据管理模块,包括数据的存储、读取和查询等操作,以支持后续的数据分析和可视化需求。
(3)数据分析与建模:利用Spark的分布式计算能力,设计和实现数据分析模块,应用机器学习算法、统计分析方法等,对股票市场数据进行分析和建模。并且实现股票价格预测、市场趋势分析、相关性分析等功能,为投资决策和风险控制提供支持。
(4)可视化与交互:设计和实现可视化模块,通过图表、图形等方式将股票市场数据以可视化形式展示。其次提供交互式界面,允许用户自定义数据展示、进行数据筛选和排序,以及与可视化结果进行交互操作。
(5)性能优化扩展以及评估:对系统进行性能优化以及扩展性,通过合理的数据分区、并行计算和缓存机制的调配,提高数据处理和分析的效率,以及考虑系统的扩展性,支持处理更大规模的股票市场数据和更复杂的分析任务,并分析和总结实验结果,评估系统的准确性、效率和用户体验
基于以上分析,本设计系统的大致结构如下图1所示:

图1 功能结构图
2.课题研究拟采取的方法
本课题将采用的技术方法包括:面向对象方法论、软件系统分析与设计、可视化建模、程序设计、数据库技术、计算机网络技术以及中英文写作能力,并借鉴了目前已有的一些高校与社区的系统进行设计。
(1)文献法研究法:通过调查与网页设计制作相关的文献,对其进行一个综合性的了解,同时吸收文献中对网页设计制作的独特见解,加入自身的理解,从而达到更高的程度。
(2)描述性研究法:将网上已有的网页制作的经验、理论以及规律甚至是小技巧等等通过自己的理解,并给予实施验证。
(3)实验研究法:对网站的各个功能模块进行软件测试。
本系统的设计将会采用查阅书籍、浏览网站资料、前往企业现场等方式来对系统的实现进行研究和梳理,通过对实际企业员工进行用户交流、考察提高用户体验以及系统功能的设计和改进。
论文撰写方面将会通过调查法、观察法、经验总结法等,对收集到的信息和资料进行梳理,结合实际的系统设计、实现和测试维护进行论证,最终在导师的指导下完成论文的撰写。
四、课题研究中的主要难点及解决办法
1. 数据处理和存储
股票市场的数据量庞大且变化频繁,对数据的处理和存储提出了挑战。解决办法可以包括:
(1)数据分区和分片:使用Spark的分布式计算能力,将大规模数据划分为多个分区,实现并行处理和计算。
(2)高效存储:选择适合大数据处理的分布式存储系统,例如Hadoop Distributed File System(HDFS)或Apache Parquet,以实现高性能的数据读写和查询。
2. 数据清洗和转换
原始股票数据可能存在缺失值、异常值和噪声等问题,需要进行数据清洗和转换。解决办法可以包括:
(1)缺失值处理:通过插值、删除或填充缺失值的方法来处理缺失数据。
(2)异常值检测和处理:使用统计方法或机器学习算法来检测和处理异常值。
(3)特征工程:对原始数据进行特征提取、转换和降维,以便更好地适应数据分析和可视化需求。
3. 大数据分析算法
股票市场的数据具有复杂性和高维性,选择合适的大数据分析算法是一个挑战。解决办法可以包括:
(1)机器学习算法:使用机器学习算法,如回归、分类、聚类和时间序列分析等,来预测股票价格、研究市场趋势和发现相关性。
(2)图计算算法:利用图计算算法,如PageRank算法和社区发现算法,分析股票市场的网络结构和关联关系。
(3)高性能计算:通过合理的算法设计和并行计算技术,充分利用Spark的计算能力,提高大数据分析的效率和准确性。
基于以上分析,本设计中使用了k均值算法,如图2。

图2 k均值算法流程图
4. 可视化设计和交互性
将股票大数据以可视化形式呈现给用户,需要考虑设计合理的可视化方法和提供良好的交互性。解决办法可以包括:
(1)可视化技术选择:选择合适的可视化图表、图形和布局,以准确传达数据的含义和趋势。
(2)用户交互设计:设计交互式界面,提供用户友好的操作方式,例如缩放、过滤、排序和联动等功能,以便用户深入探索和分析数据。
(3)可视化性能优化:对大规模数据的可视化进行性能优化,避免过多的计算和绘制,以提高系统的响应速度和用户体验。
以上是在研究基于Spark的股票大数据分析及可视化系统时可能遇到的主要难点及相应的解决办法。通过深入研究和充分利用Spark的分布式计算能力,结合合适的数据处理、分析算法和可视化技术,可以克服这些难点,实现一个高效、准确和用户友好的股票大数据分析及可视化系统。
五、进度安排
1、选题与需求分析阶段(2023.09.11-2023.10.22)
2023.09.11-2023.09.24:完成技术调查与选题。
2023.09.25-2023.10.22:完成《开题报告》、《项目需求说明书》。
2、系统设计阶段(2023.10.23-2023.12.17)
2023.10.23-2023.11.19:进行概要设计并撰写《概要设计说明书》。
2023.11.20-2023.12.17:进行详细设计并撰写《详细设计说明书》、《中期检查报告》。
3、系统实现阶段(2023.12.18-2024.03.31)
2023.12.18-2024.03.17:完成系统编码和单元测试。
2024.03.18-2024.03.31:完成系统的集成测试并修改bug。
- 毕业设计答辩阶段(2024.04.01-2024.06.20)
2024.04.01-2024.05.31:撰写毕业设计论文。
2024.06.01-2024.06.14:修改毕业论文,制作答辩PPT。
2024.06.15-2024.06.20:毕业答辩。
目 录
摘 要
Abstract
第1章 前 言
1.1 项目的背景和意义
1.2 研究现状
1.3 项目的目标和范围
1.4 论文结构简介
第2章 技术与原理
2.1 开发原理
2.2 开发工具
2.3 关键技术
第3章 需求建模
3.1 系统可行性分析
3.2 功能需求分析
3.3 非功能性需求
第4章 系统总体设计
4.1 系统总体目标
4.2 系统架构设计
4.3 数据库设计
第5章 系统详细设计与实现
5.1 实现系统功能所采用技术
5.2 用户模块设计
5.3 自媒体人模块设计
5.4 后台管理员模块设计
第6章 系统测试与部署
6.1 测试内容
6.2 测试报告
6.3 系统运行
第7章 结论
7.1 总结
7.2 展望
参考文献
致 谢
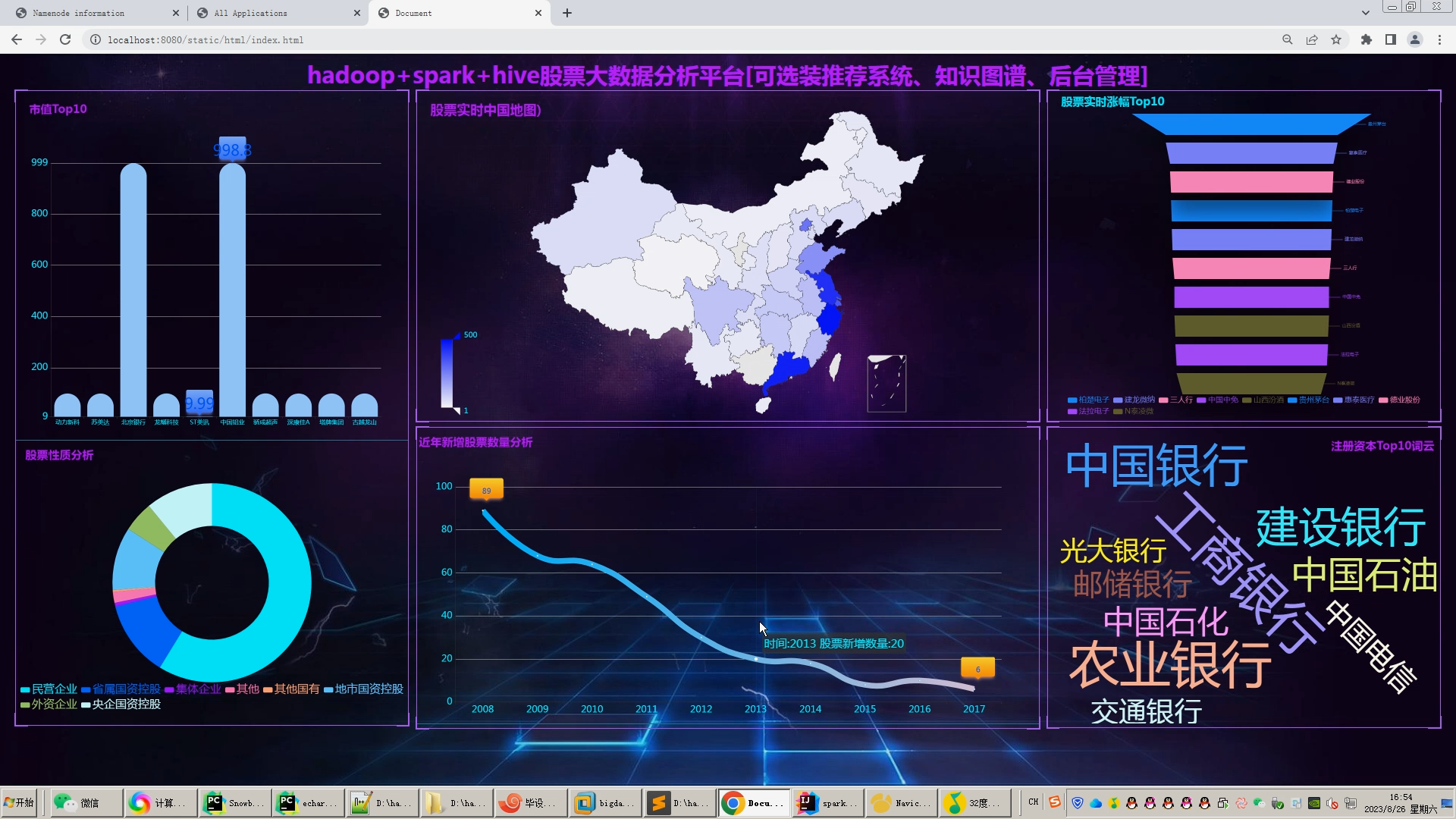



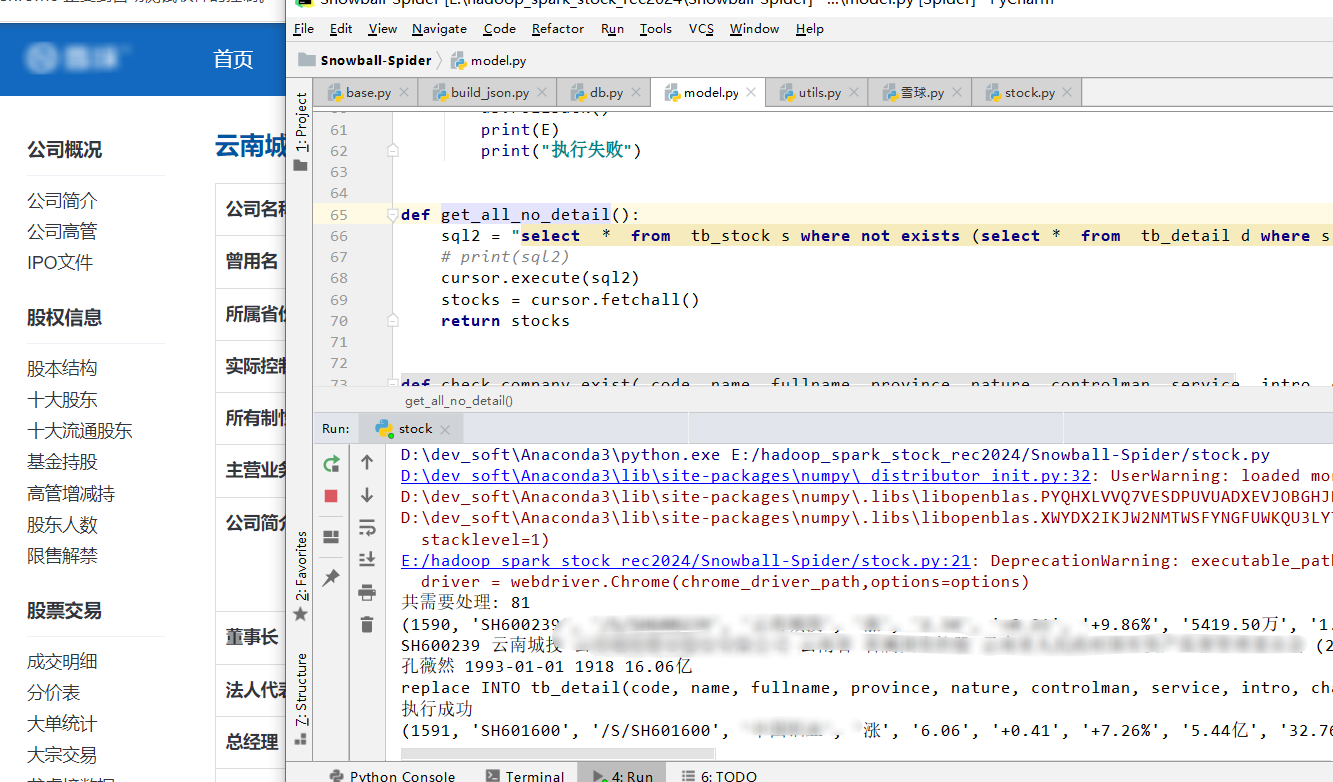

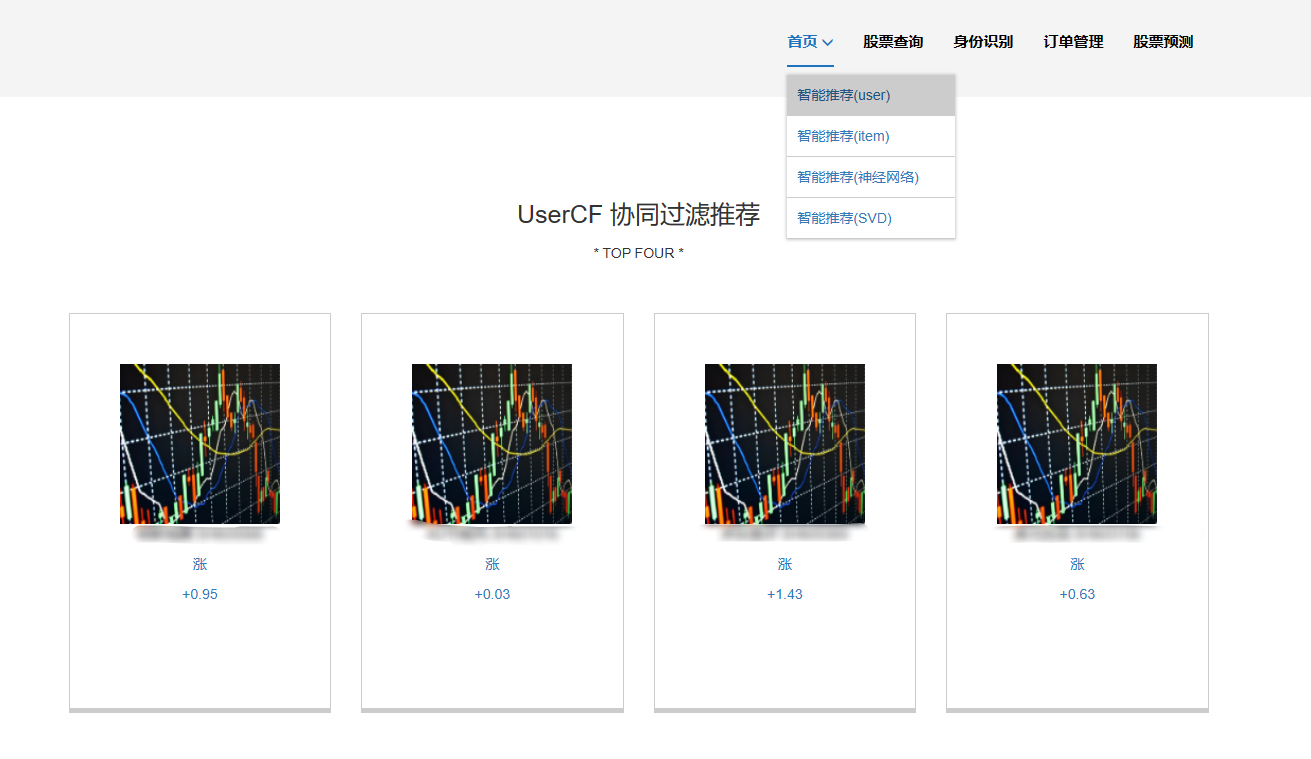

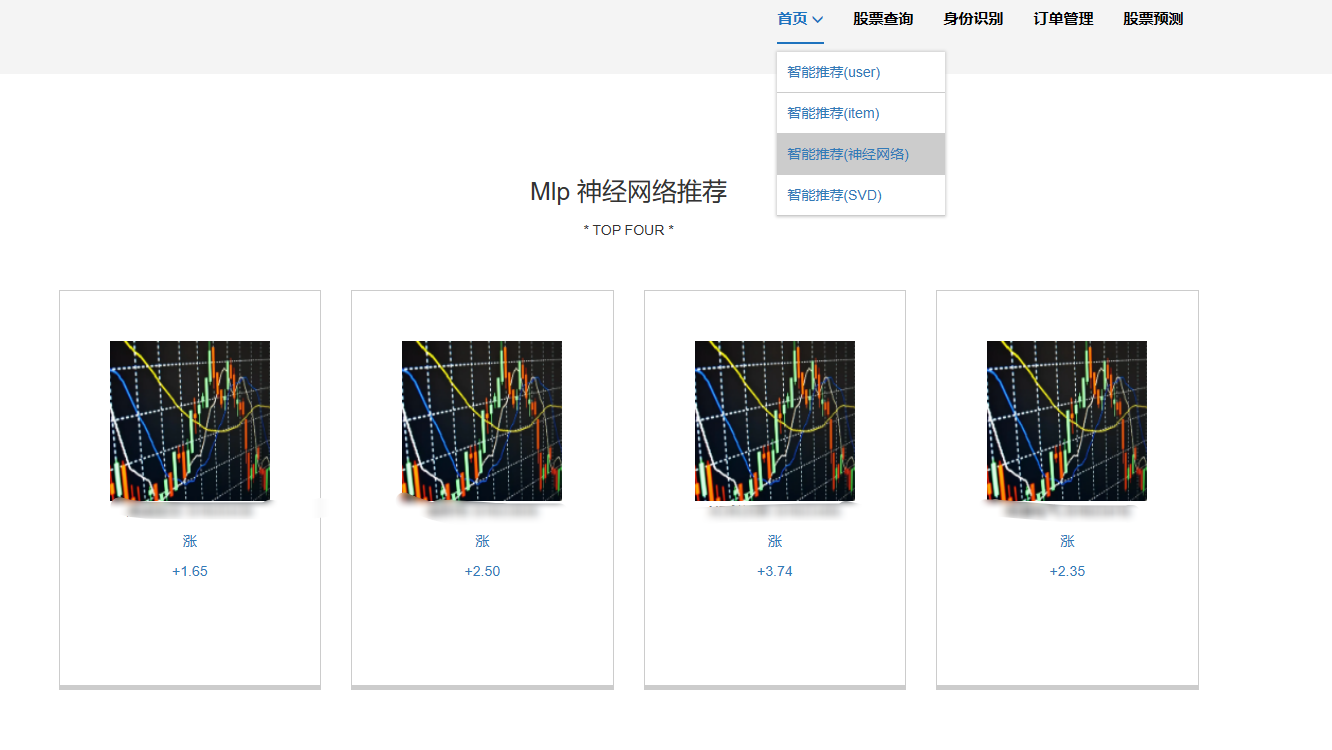


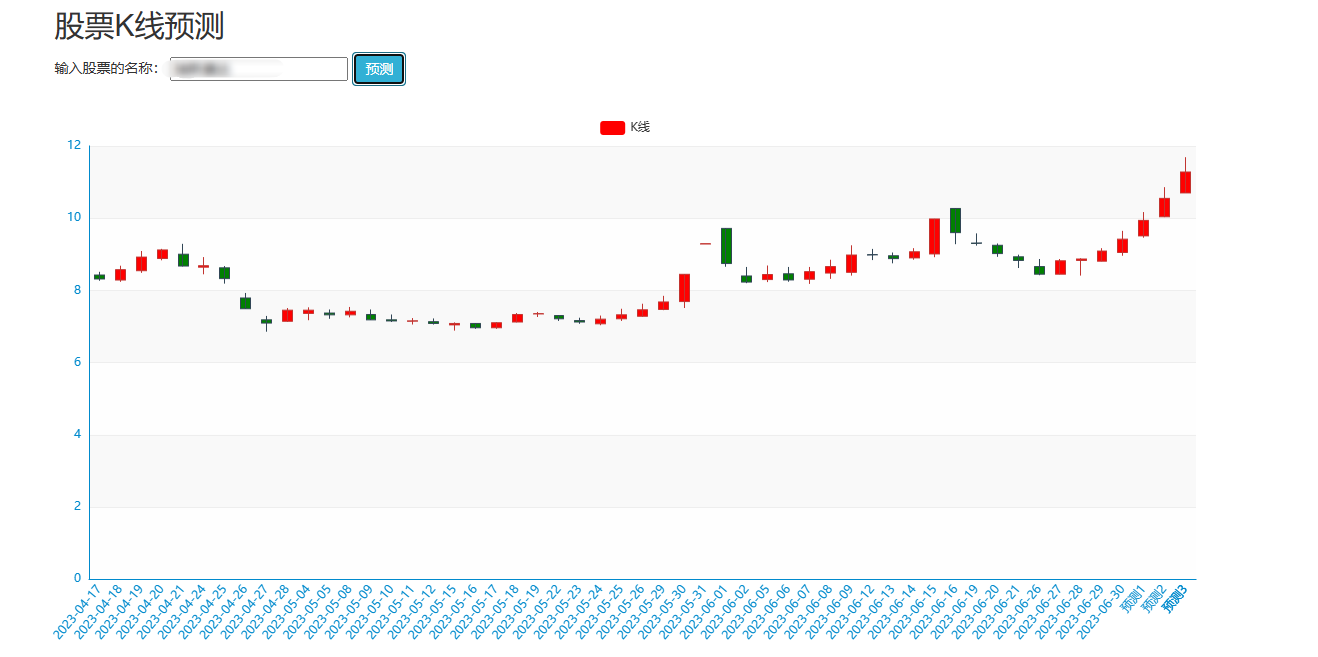

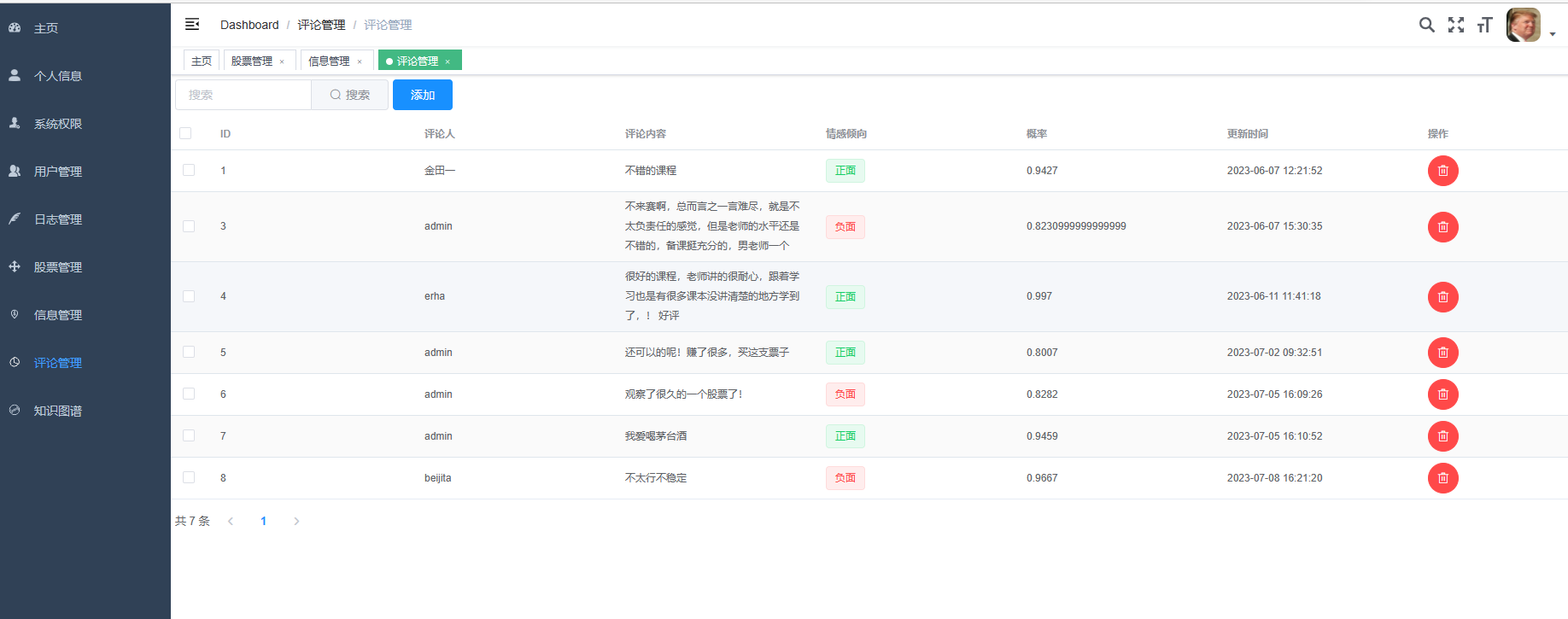
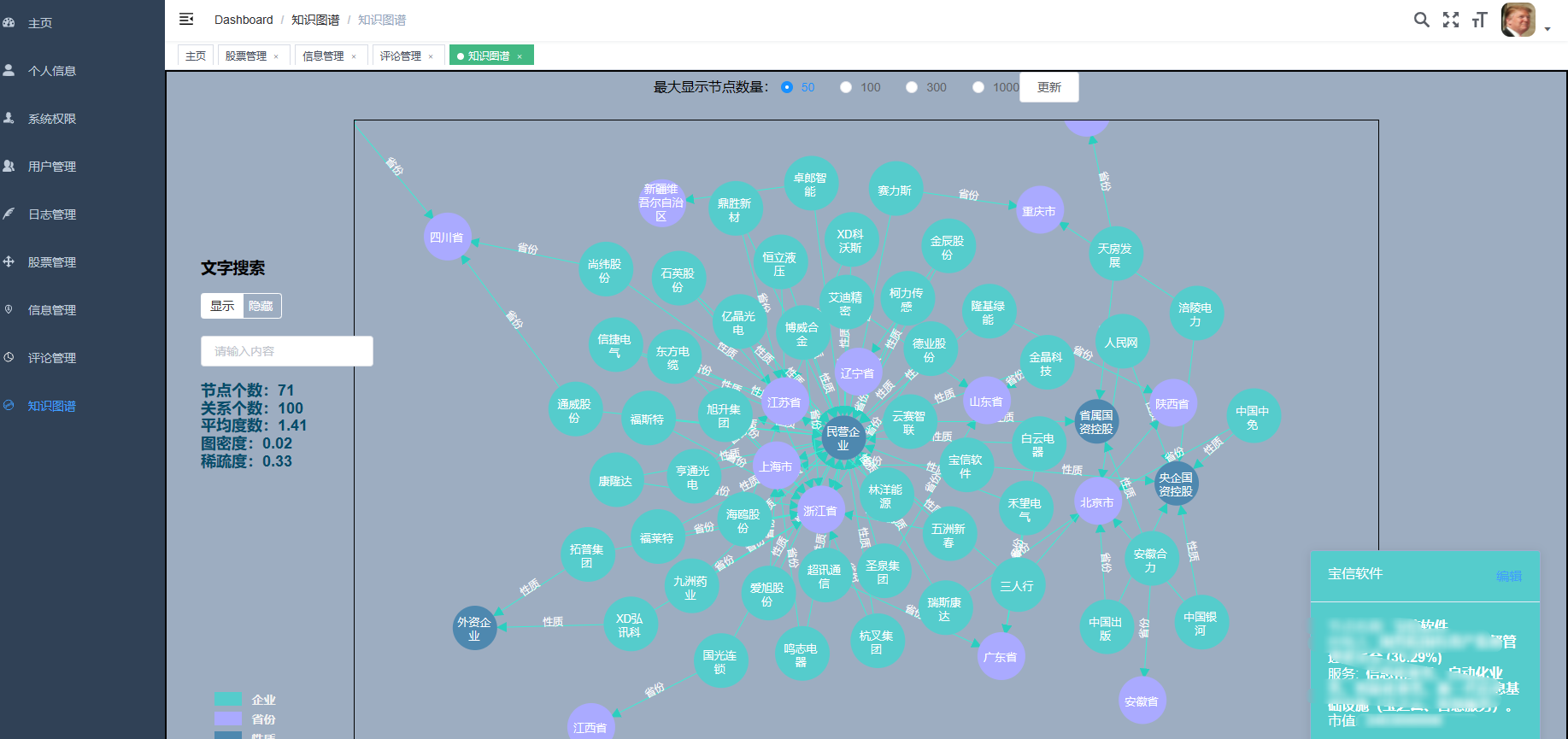


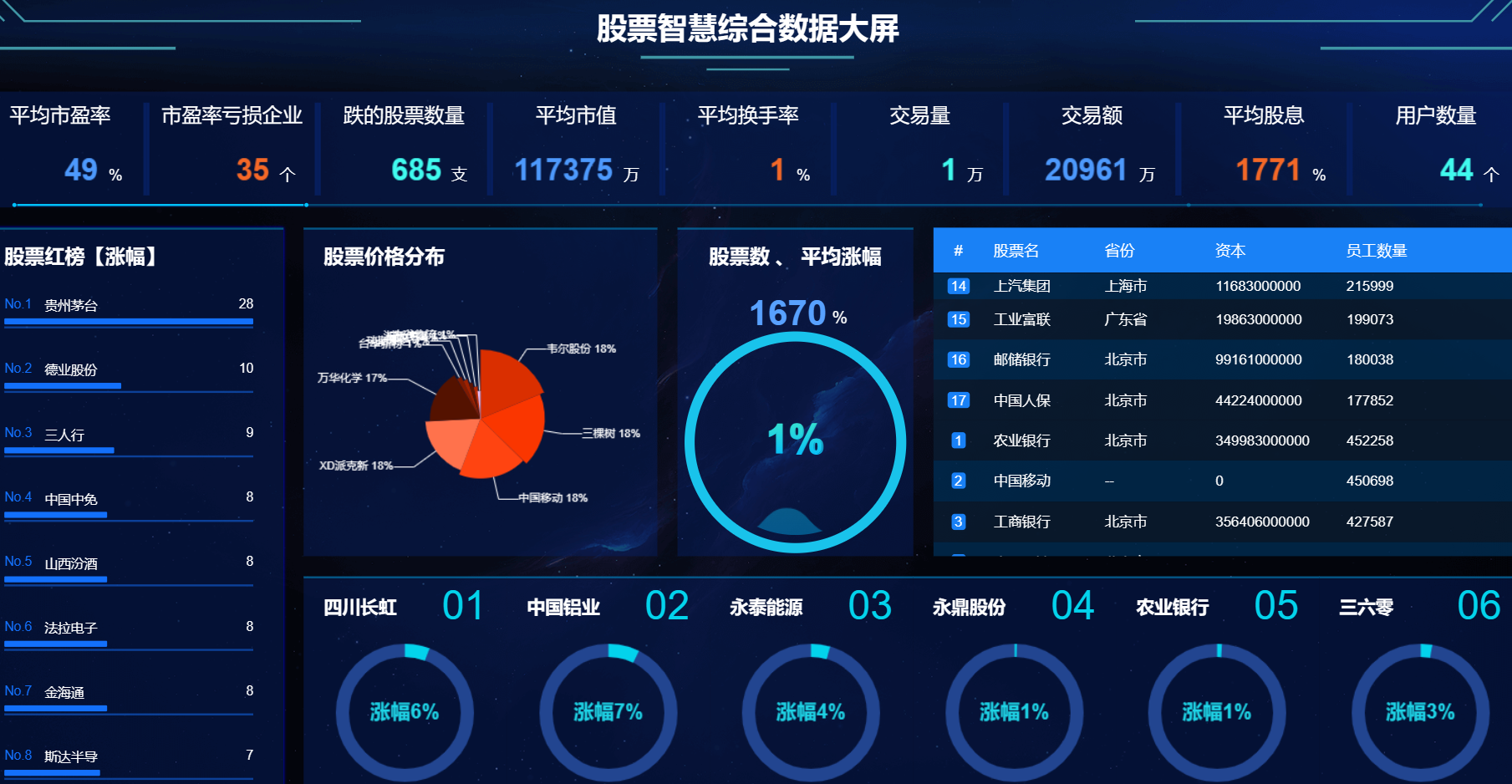
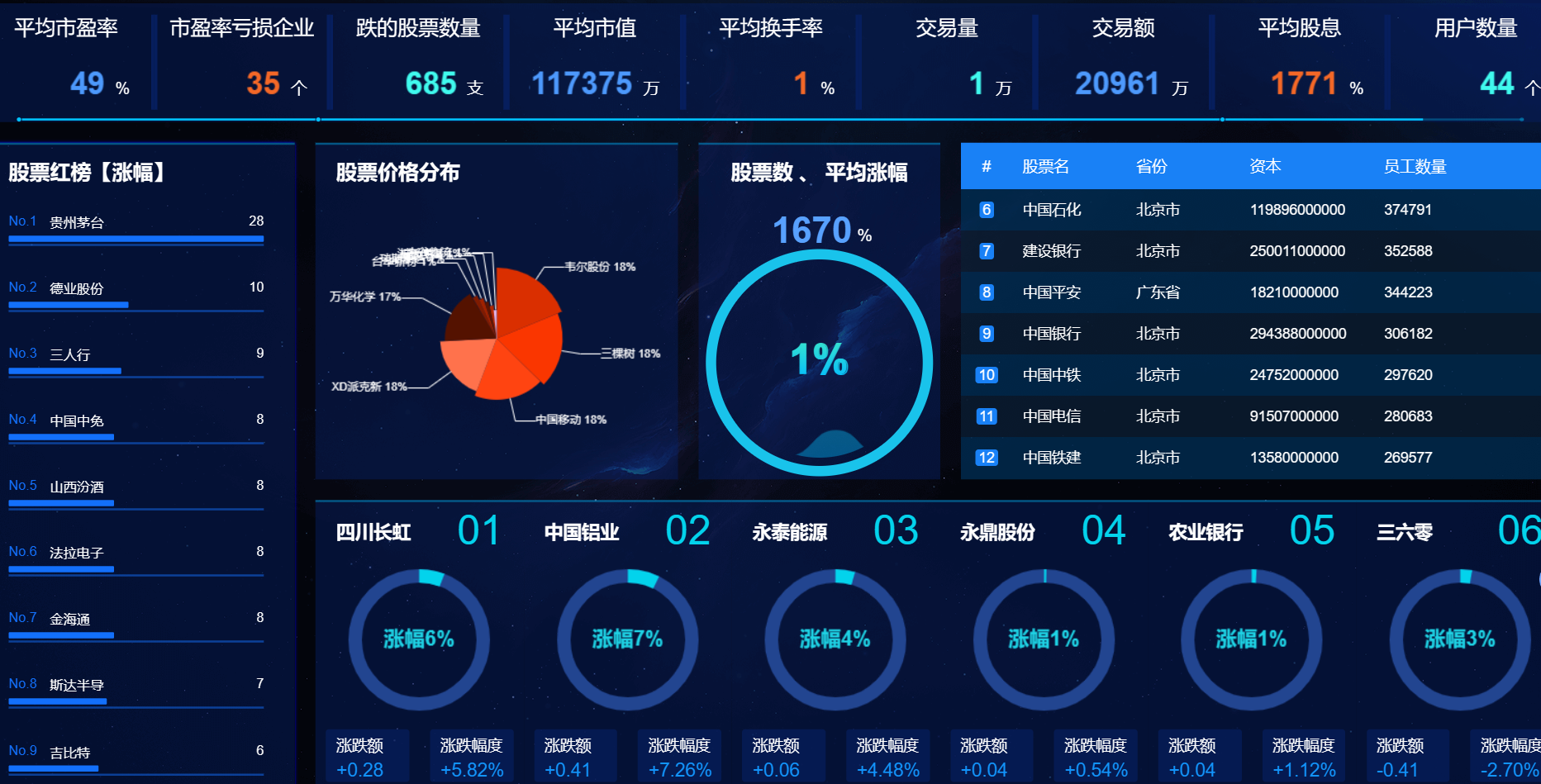
核心算法代码分享如下:
package com.sql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.junit.Test
import java.util.Properties
class StockSpark2024 {
val spark = SparkSession.builder()
.master("local[12]")
.appName("股票大数据Spark分析2024")
.getOrCreate()
val stocks_schema = StructType(
List(
StructField("id", IntegerType),
StructField("code", StringType),
StructField("link",StringType),
StructField("name", StringType),
StructField("flag", StringType),
StructField("now_price",StringType),
StructField("diff_volume", StringType),
StructField("diff_ratio", StringType),
StructField("trading_volume", StringType),
StructField("business_volume", StringType),
StructField("trunover_ratio", StringType),
StructField("pe_ratio", StringType),
StructField("dividend_ratio", StringType),
StructField("marketvalue", StringType),
StructField("s0", FloatType),
StructField("s1", FloatType),
StructField("s2", FloatType),
StructField("s3", FloatType),
StructField("s4", FloatType),
StructField("s5", FloatType),
StructField("s6", FloatType),
StructField("s7", FloatType),
StructField("fullname", StringType),
StructField("province", StringType),
StructField("nature", StringType),
StructField("chairman", StringType),
StructField("ctime", StringType),
StructField("capital", FloatType),
StructField("members", FloatType)
)
)
val stocks_df = spark.read.option("header", "false").schema(stocks_schema).csv("hdfs://bigdata:9000/stock2024/stocks/stocks.csv")
@Test
def init(): Unit = {
stocks_df.show()
}
//指标6 近年新增股票数量分析
@Test
def tables06(): Unit = {
stocks_df.createOrReplaceTempView("ods_stocks")
val df2 = spark.sql(
"""
select tt.ctime,count(distinct name) num
from(
select date_format(ctime,'yyyy') ctime,name
from ods_stocks
) tt
group by tt.ctime
order by tt.ctime desc
limit 10
""")
df2
// .show(50)
.coalesce(1)
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://bigdata:3306/hive_stock?useSSL=false",
"tables06",
new Properties()
)
}
}